jazz (re900)
“Advanced Super Secure Cipher” - Rust Go With It!
Author k4iz3n
This was a reversing challenge on a Rust binary. There were only 16 solves but I personally think there could have been more, since it was not stripped. Perhaps it was due to the lack of good tools to analyse Rust binaries. Hopefully this writeup shows some helpful steps to make the reversing process easier.
Setup
As the binary does not receive any input from stdin, I guessed that it takes the input from the program arguments, and I was right about it as it prints Nope when I gave a dummy input value.
> ./jazz
Night and stars above that shine so bright ...
Please say something ...
> ./jazz inctf{}
Night and stars above that shine so bright ...
Nope
Unreadable function names
Upon loading the binary in Ghidra, I searched for the strings in the output and came across a function with the name h655cc631b7a9a767. However, there is the full function name in the comments, as shown below. Not sure why Ghidra does it like this, but it surely is a problem when trying to reverse the binary, even though it is not stripped.
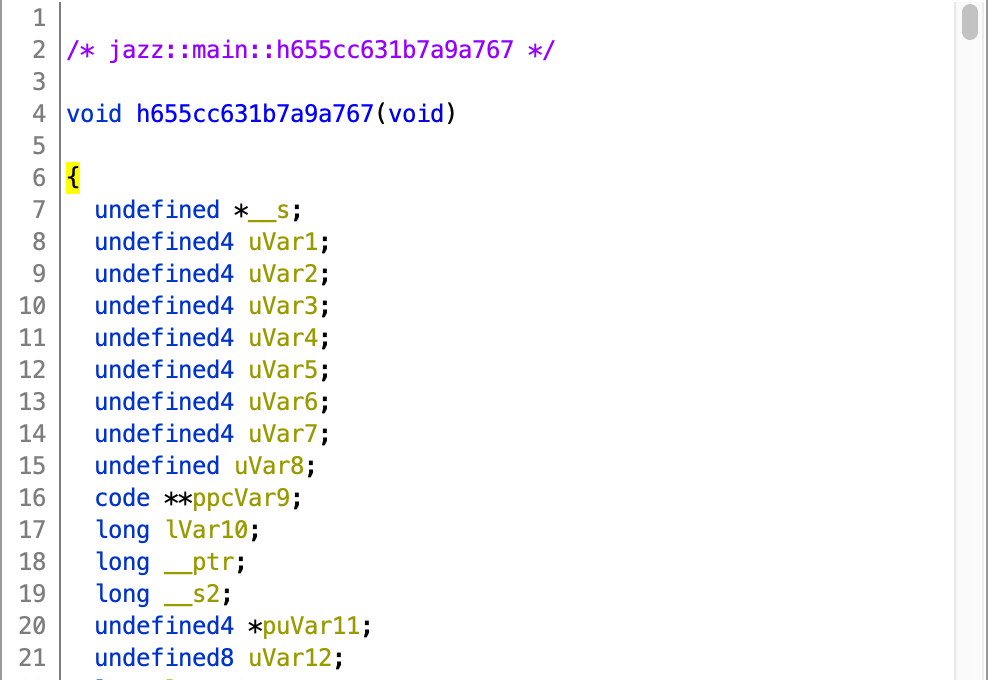
On the other hand, there are function names that look like _ZN5alloc7raw_vec19RawVec$LT$T$C$A$GT$11allocate.... Those familiar with C++ would find this name mangling familiar. Ghidra supports demangling C++ symbols so this is not an issue when reversing C++ binaries. However, Ghidra doesn’t support name demangling for Rust binaries, which is the second problem.
This is annoying enough that I decided it would be worth the effort to make a script to rename all the functions to a readable format, resolving the two problems mentioned above. You can check out my fork of the ghidra_scripts repository by Ghidra Ninja to get this script. Make sure to install rustfilt on your system for the script to work properly.
After running the script, all the symbols should be way clearer.
Stack frame size is wrong
There is another problem with the decompilation. As shown in the image below, although in the disassembly it shows that [rsp + 0x30] is being dereferenced, like a normal stack variable, but in the decompilation it is accessed very weirdly through *(undefined8 *)(&stack0x00000000 + lVar10). And this generally applies to almost every local variable throughout the function.
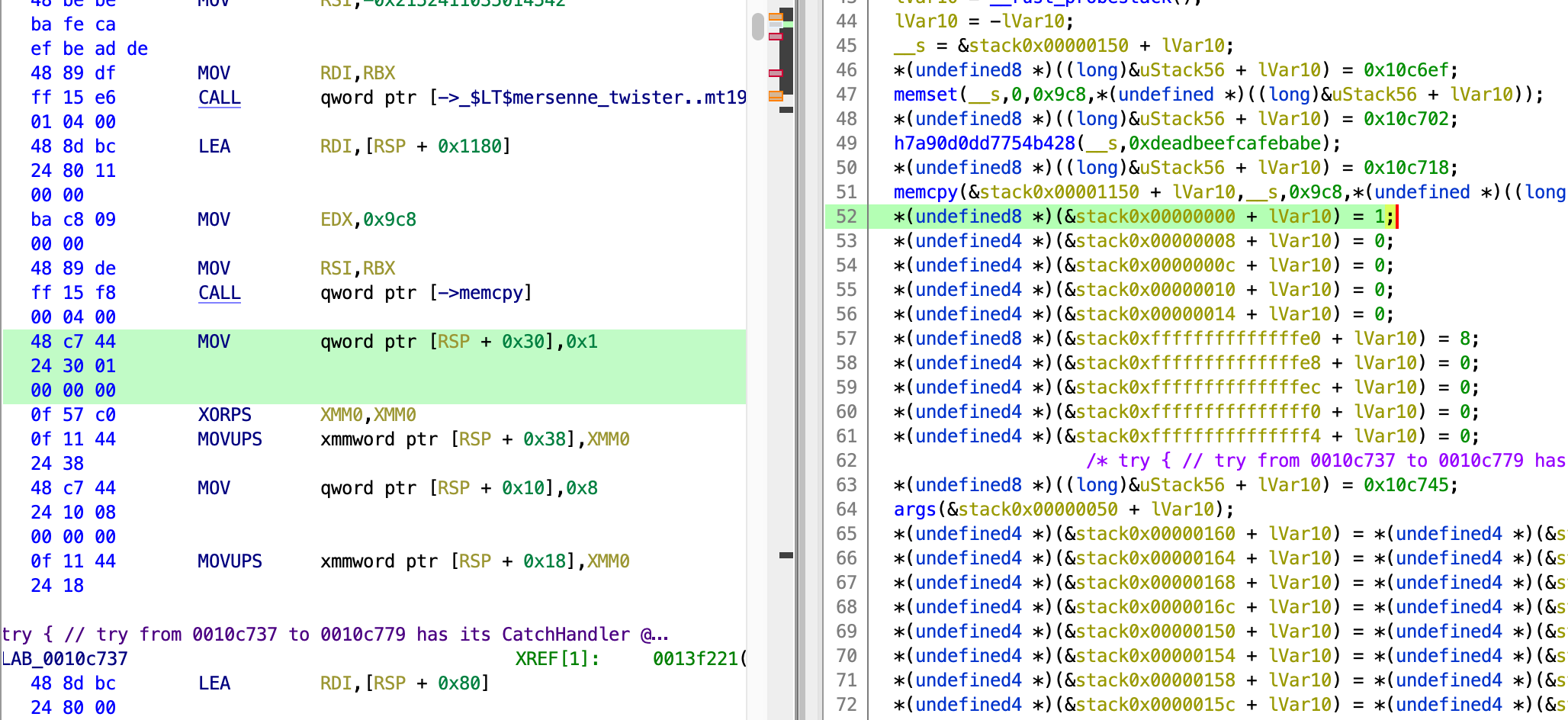
This is problematic because Ghidra doesn’t manage to correctly detect the stack frame size, hence not recognizing things like [rsp+0x30] as local variables. As a result, everything that looks like *(undefined8 *)(&stack0x00000000 + lVar10) cannot be renamed. Reverse engineering without the ability to rename variables just feels impossible.
After investigating a bit, I realized that __rust_probestack(), which modifies the value of rsp, was called at the start of the function. Ghidra didn’t manage to detect this change in the stack pointer, as reflected in the stack depth value shown on the second column of the disassembly (the one with 0, 008, 010). After a few instructions, the stack depth becomes -?-, so it shows that Ghidra is unable to tell the size of the stack.
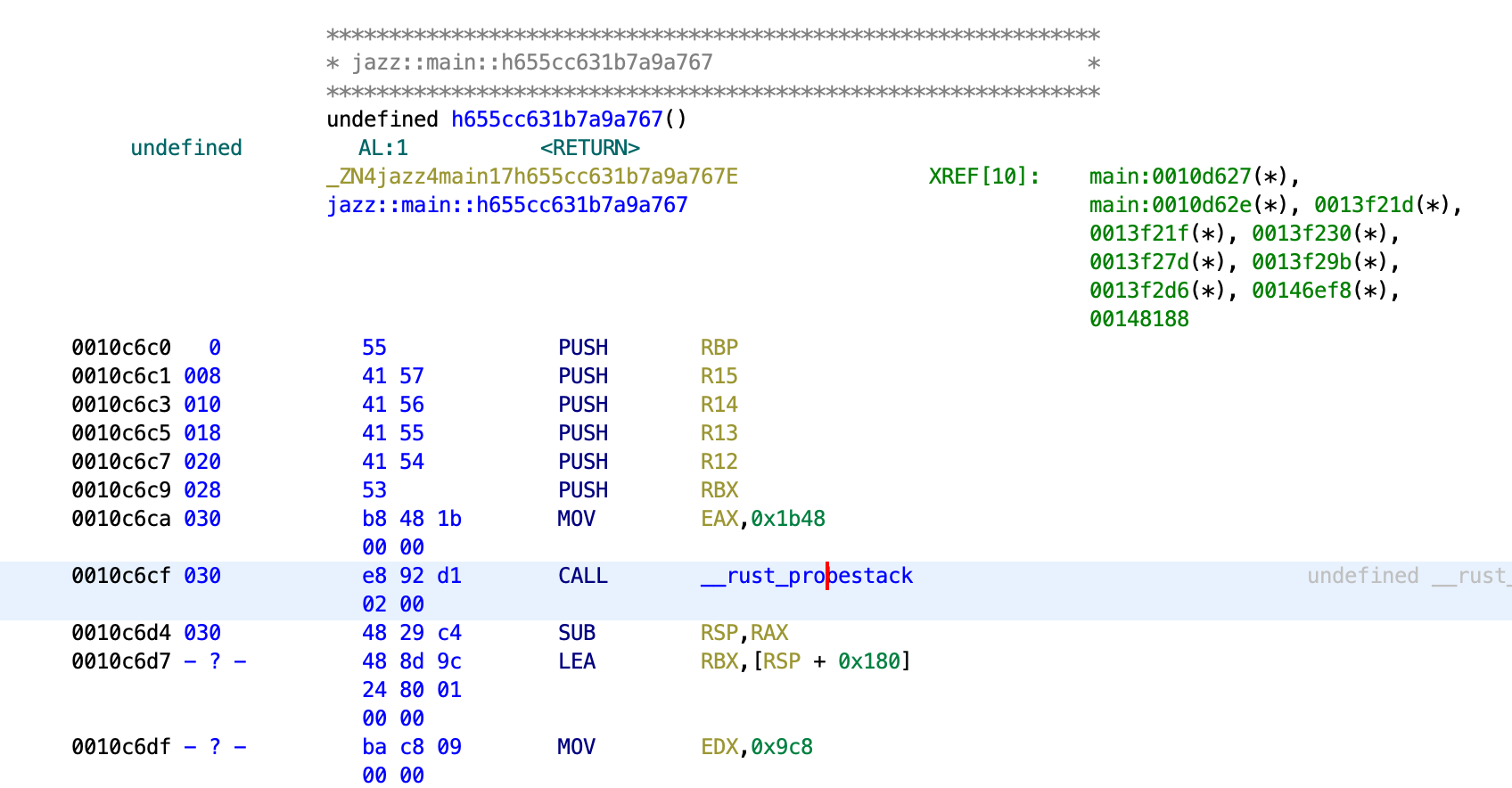
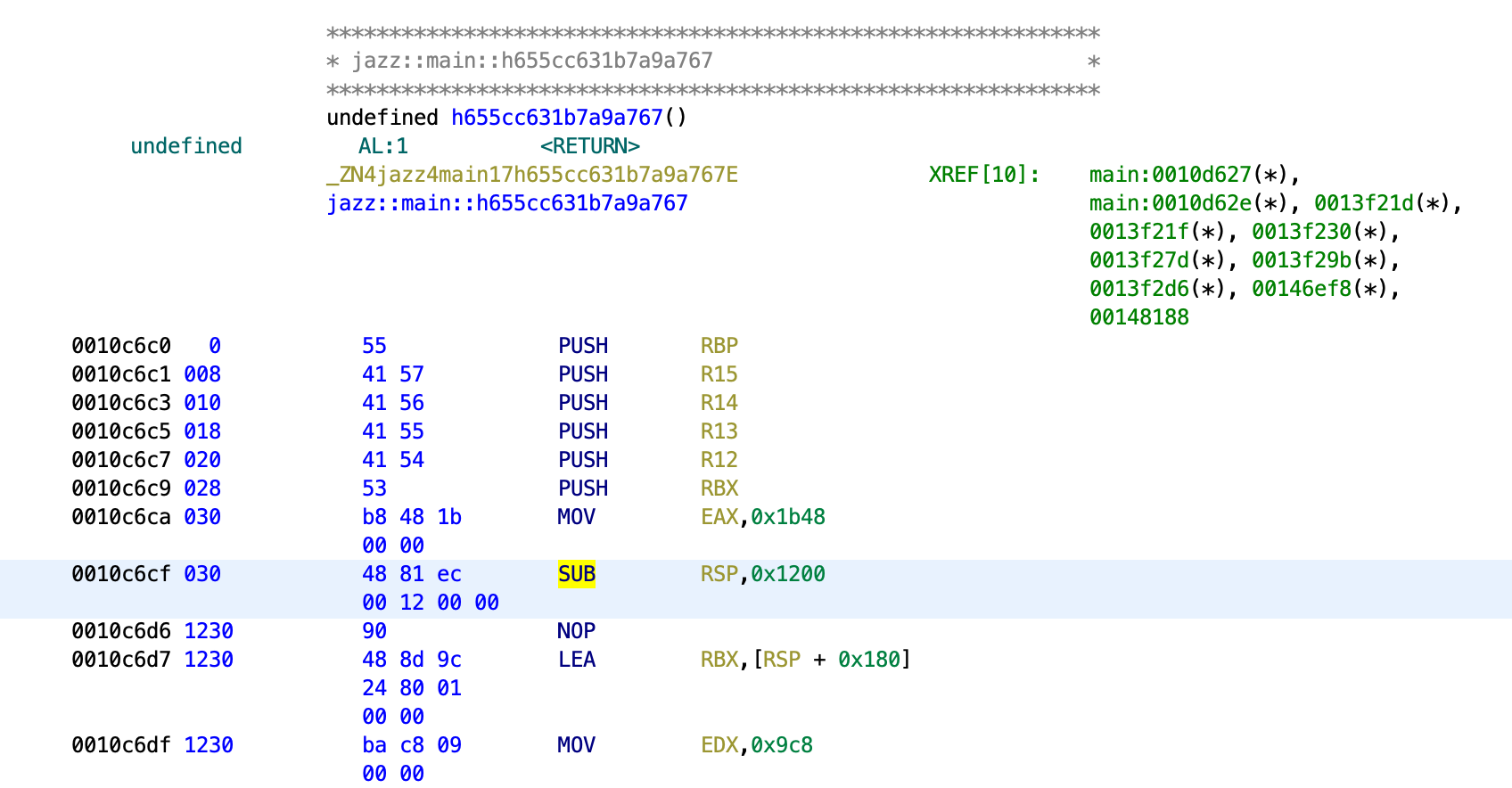
After many failed attempts to manually set the stack size, I tried to just patch the call __rust_probestack() instruction to sub rsp, 0x1200 (0x1200 just as a very large value as long as it covers all the variables), and it worked. Ghidra is now able to recognize all the local variables in the function.
Reversing
Getting a big picture
Now with all the setup done, I can start going through the decompilation to see what the program is doing.
Taking a look at the start of the function, there are many stack variables being set, which can be distracting usually. From experience, it is fine to ignore these small details, and look for things that stand out. In the image below, I see a call to <mersenne_twister...>::reseed(), std::env::args(), <alloc::vec::...>::from_iter, and std::io::stdio::print.
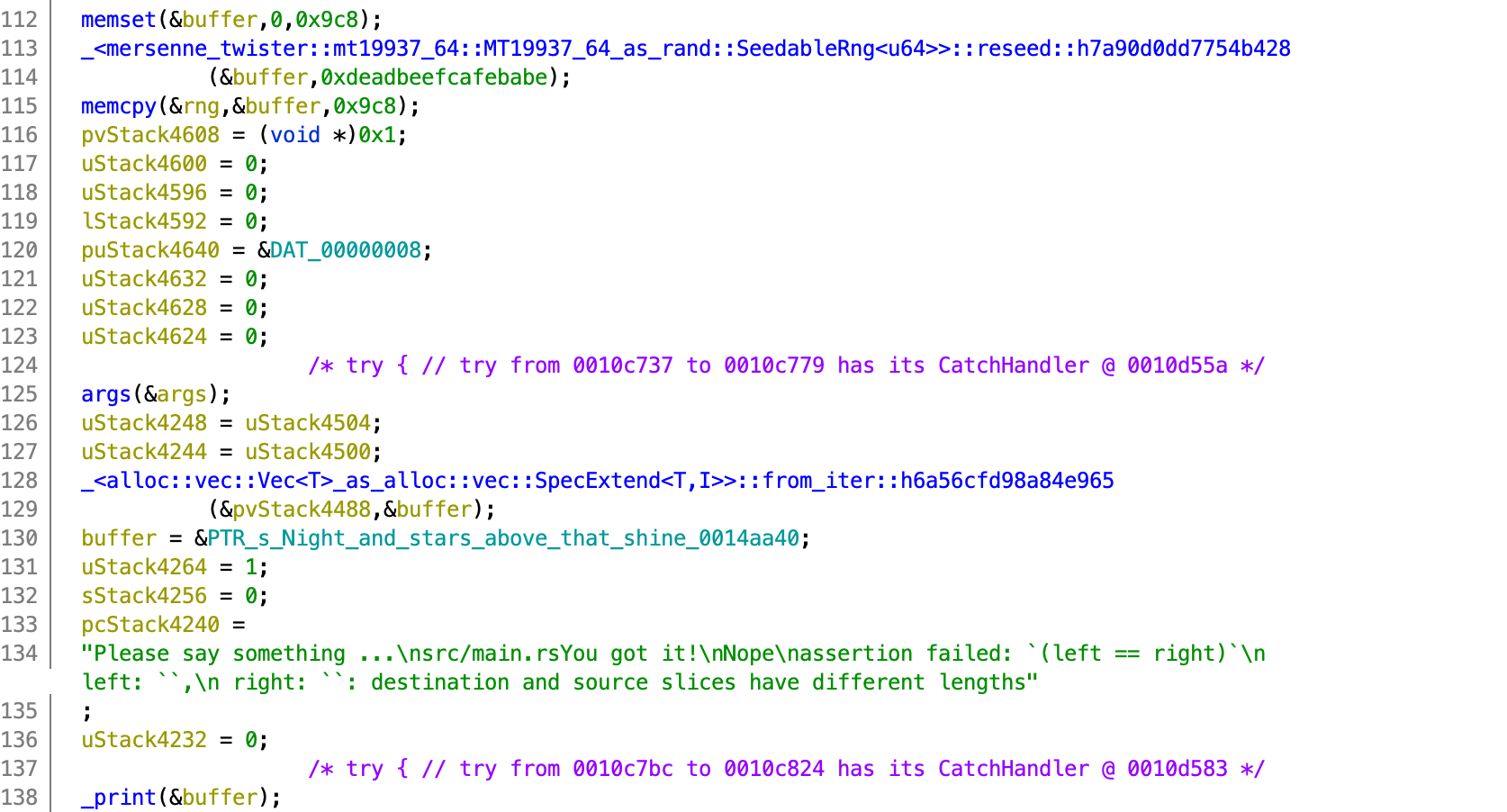
So I can tell that the program is
- Preparing an MT19337 random number generator
- Loading the program arguments
- Printing the starting message(
Night and stars...) that is seen when running the program.
Normally it is fine to ignore container methods such as <alloc::vec::...>::from_iter at the start too, as they could just be for modifying the internal state of a container, which is generally not important to know what the program is doing.
Moving on, we can see a value compared with 1, which is most likely the number of arguments passed to the program. This can be easily verified by inspecting in a debugger. Then, something similar to identity permutation of the RC4 key scheduling algorithm is being prepared. It is not easily seen on first glance but can be verified by inspecting the memory in a debugger too. Afterwards, the contents of the array are shuffled around by Rng::shuffle, resembling the KSA of RC4.
Once again, alloc::...::reserve can be ignored since it is just handling the internal state of the container, as stated in the docs.
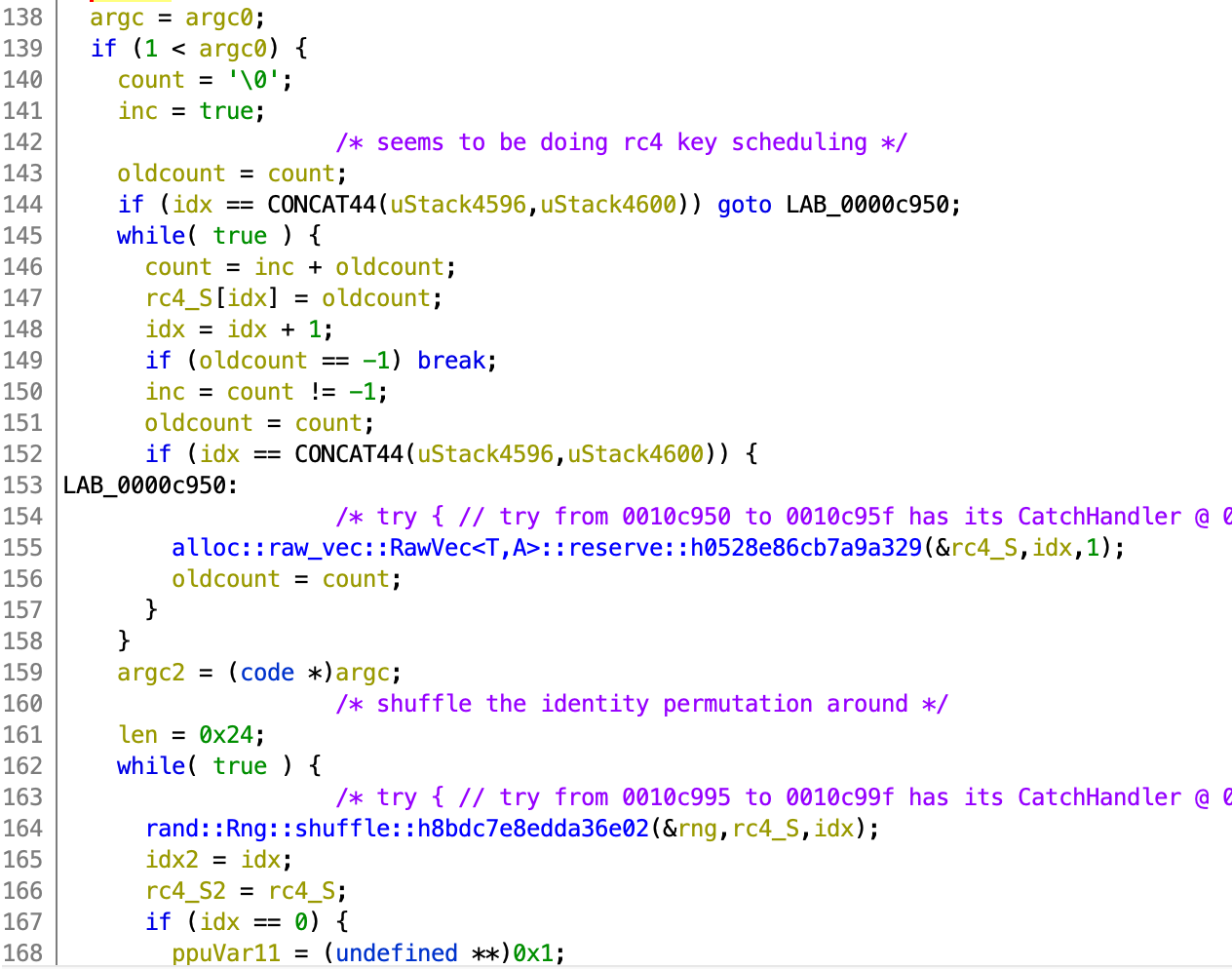
Moving on, skipping some parts of the code that looks to be primarily copying contents of one buffer to another, I reached this part of the code (refer to the 2 images below). Don’t mind the variable names as they might not really make sense, but notice that there are more complicated arithmetic operations such as %, *, and /. There is also another call to an RNG method. These operations are most likely done on the list whose contents was shuffled earlier.
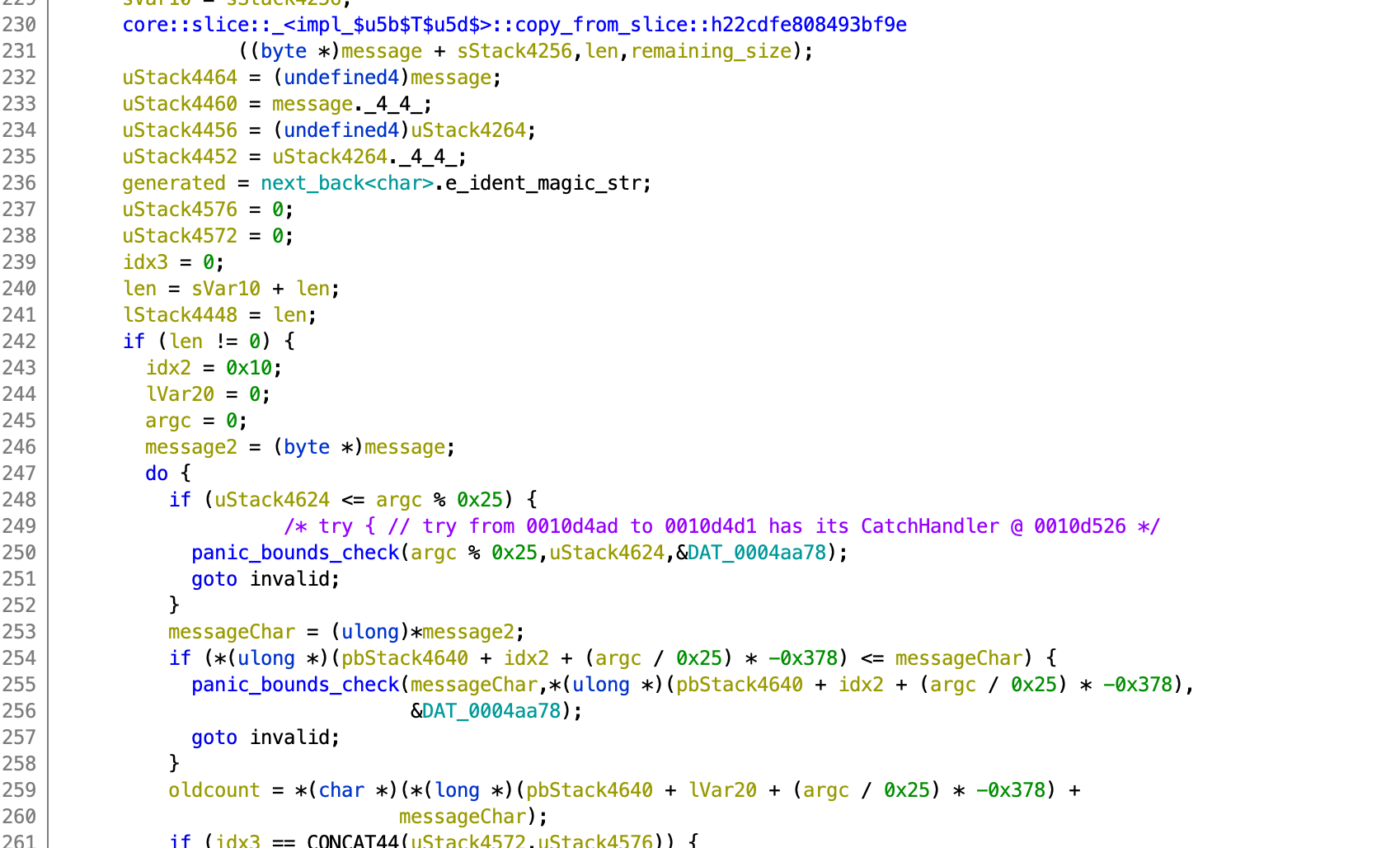
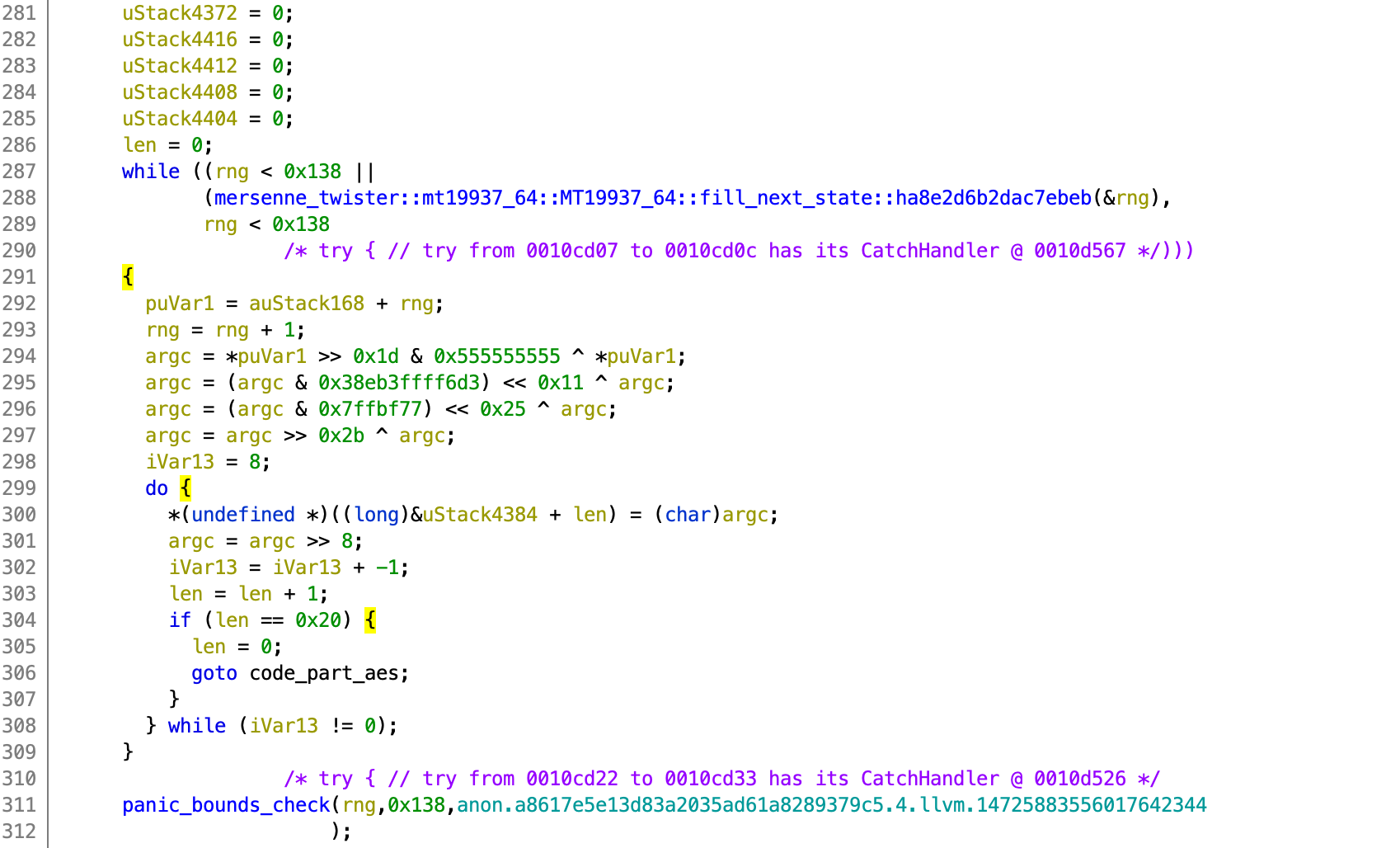
My strategy is to consider all the code above to just be generating a list of random numbers from an already somewhat random list of numbers. Normally numbers can be pseudorandomly generated by putting together some multiply and divide operations.
Moving further, I encountered an array of values. This could be MD5 magic constants, AES keys, there are many possibilities. But fast forwarding a bit, at the end of the program, I found a reference to this array by a call to bcmp, which compares the contents of two buffers.


After this comparison, the program prints either Nope or You got it! depending on the result. This obviously means this is the “correct values” that our input needs to be transformed into.
In the image below, it might not be clear that the program is printing Nope or You got it!. I guess this is how Rust handles its strings, too bad. But anyways this can be checked by inspecting the program in a debugger.
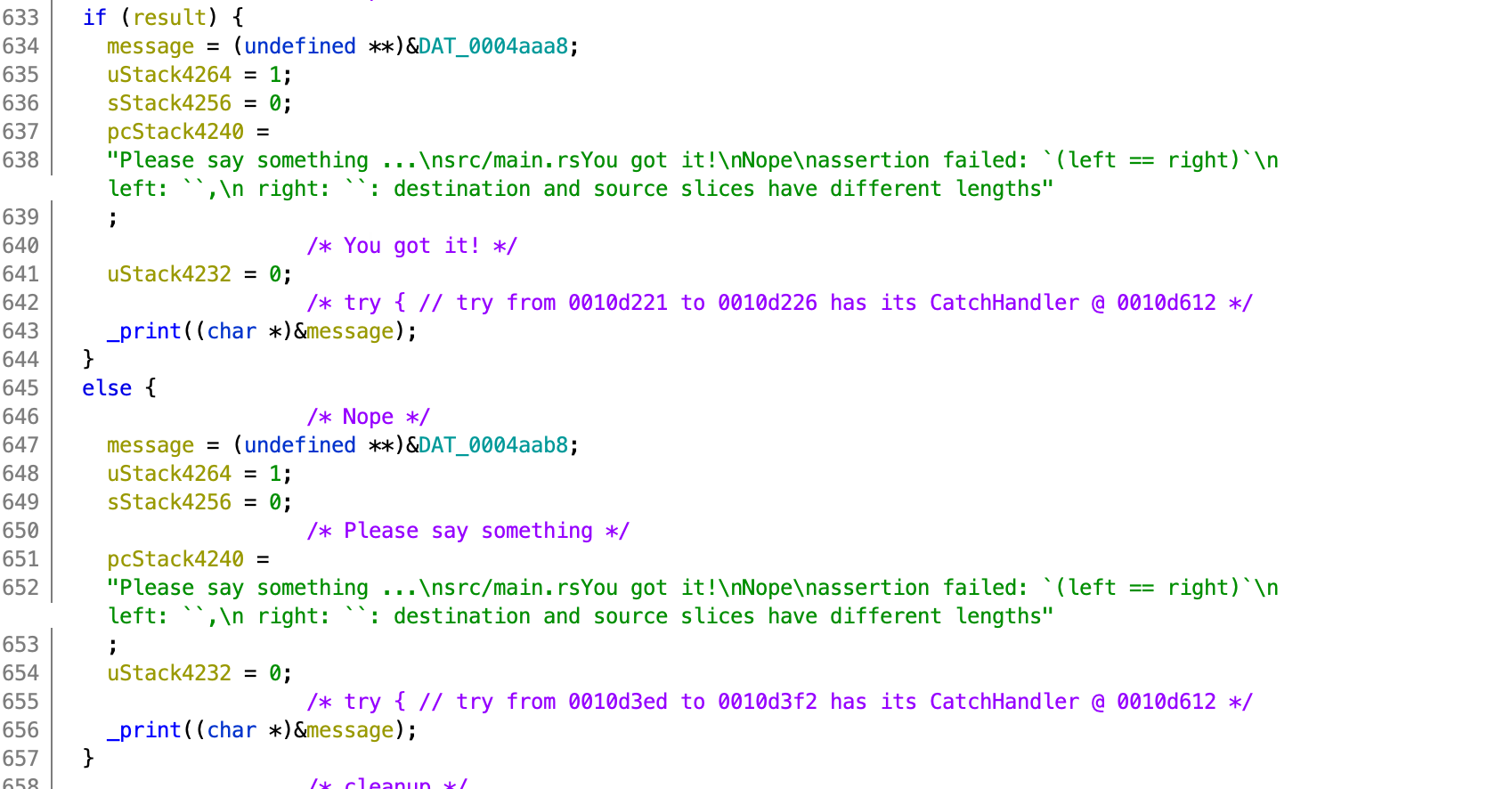
Now, I know that the program expects that the input to be transformed to a certain array of values. But so far it is not clear how is the input being transformed.
As I continued looking through the decompilation, I encountered this few lines of code that calls crypto::aes::cbc_encryptor, crypto::buffer::RefReadBuffer and crypto::buffer::RefWriteBuffer. Something to do with AES CBC encryption is happening here.
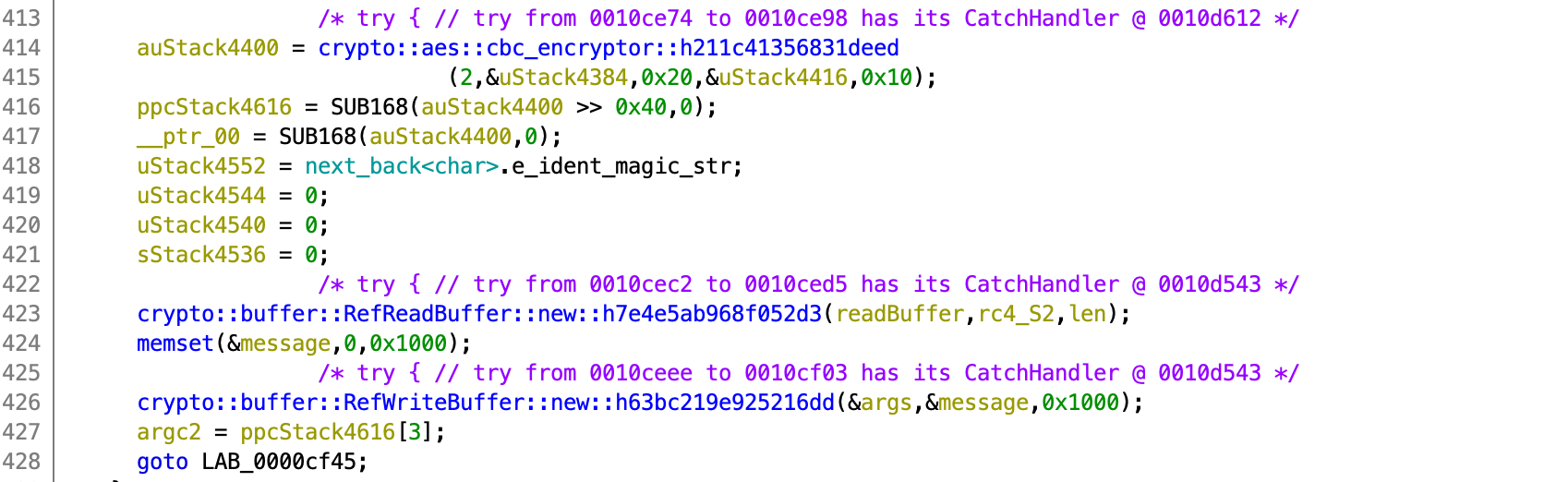
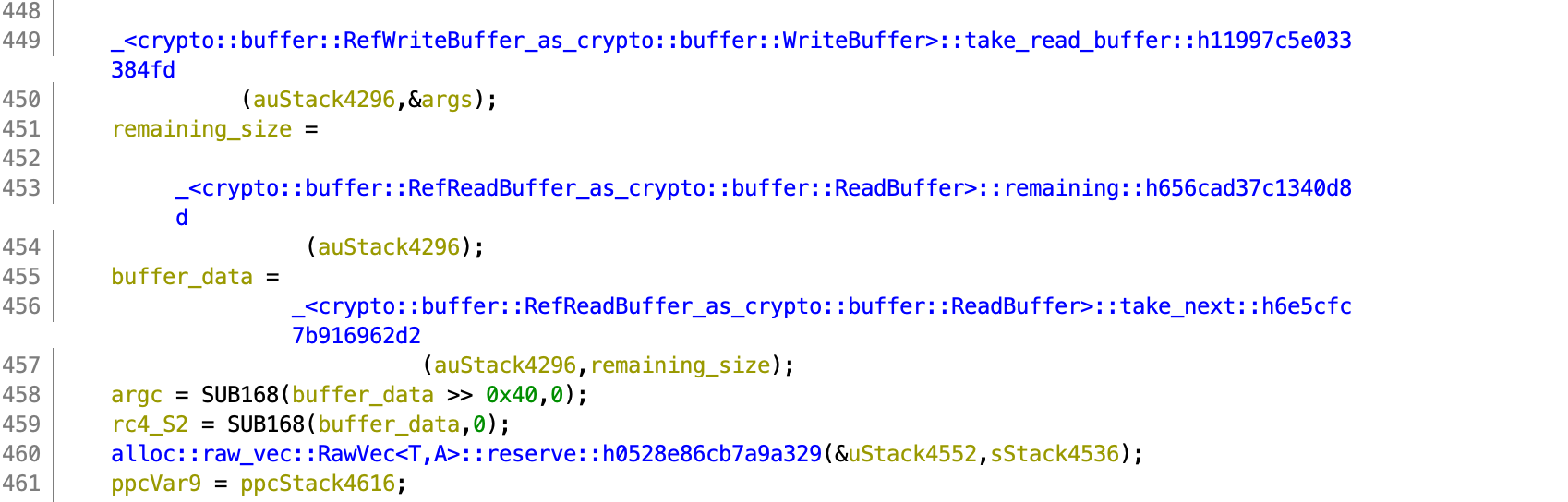
After some more copying of contents from one buffer to another as shown in the image below, which is not really important to take note of, I reached the part where bcmp was called. And this should be all of the program that is to be concerned about.

Recapping what was seen earlier, the program
- Sets up a random number generator
- Loads the program arguments
- Prints the welcome message
- Sets up a list of numbers and shuffles them around
- Does some random stuff to the list of numbers
- Sets up and performs AES CBC encryption
- Compares two arrays of values
You might wonder why is there no sign of anything being operated on the input here. So far, I managed to get a big picture of what the program is doing, but have not gotten into the specifics.
Finding out how the input is transformed
Now, I want to find out what is being done to my given input until it reaches its final form. I at least know that it will undergo AES encryption. So I shall start from there.
I suspect that the “correct array of values” is being compared with the encryption output, and will verify if this is true in GDB. I set a breakpoint to the part before the arrays are compared, and inspected the contents of the array that is being compared with the correct array.
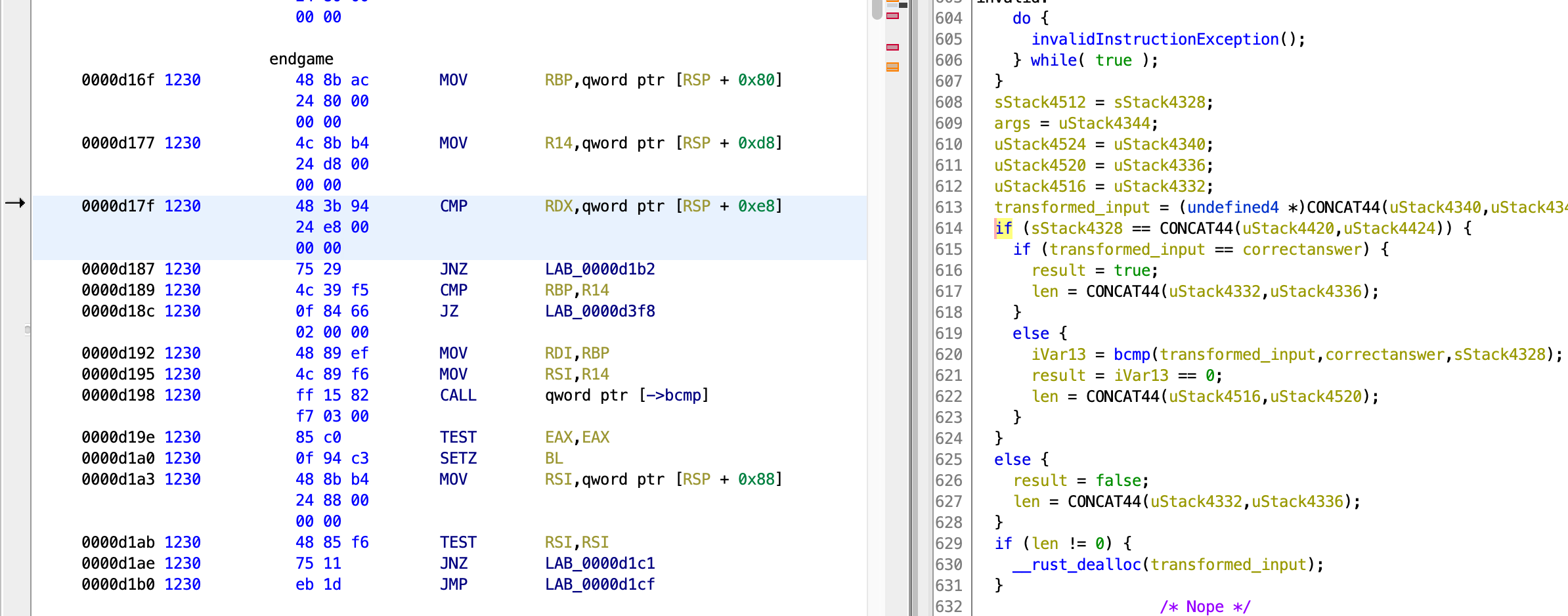
gef➤ pie break *0xd17f
gef➤ pie run inctf{}
gef➤ x/32bx $rbp
0x5555555a6350: 0xe4 0x11 0xf1 0x63 0x65 0x3e 0xbd 0xe2
0x5555555a6358: 0x89 0x01 0xa5 0xaf 0x39 0xd3 0x1d 0x88
0x5555555a6360: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555a6368: 0xa1 0xcc 0x01 0x00 0x00 0x00 0x00 0x00
Now, I check the return value of <crypto::buffer...>::take_next. I just guessed that this gives the encrypted output, being not completely sure, due to the limited documentation on docs.rs.
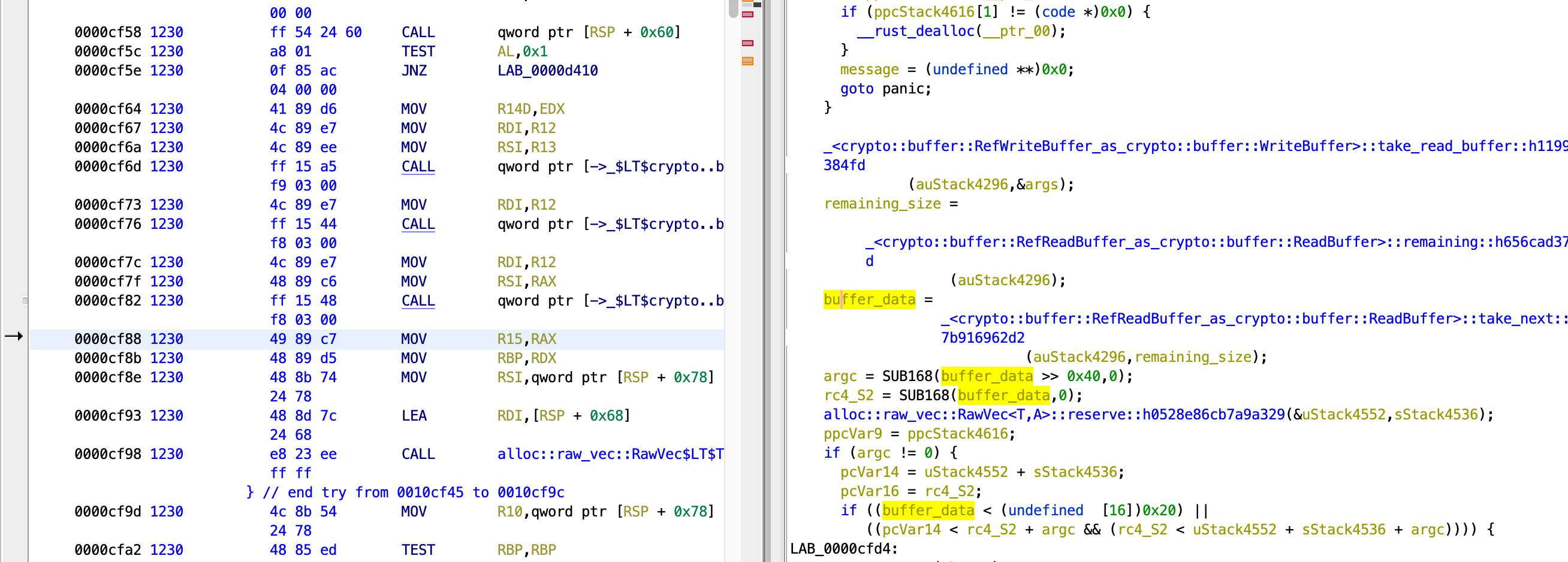
gef➤ pie break *0xcf88
gef➤ pie run inctf{}
gef➤ x/32bx $rax
0x7fffffffc8a0: 0xe4 0x11 0xf1 0x63 0x65 0x3e 0xbd 0xe2
0x7fffffffc8a8: 0x89 0x01 0xa5 0xaf 0x39 0xd3 0x1d 0x88
0x7fffffffc8b0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x7fffffffc8b8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
The contents in memory for both cases are the same. This means the output of <crypto::buffer...>::take_next is compared with the correct array. Nevertheless, I am still not sure that this is the result of AES encryption, so now I will try to look for the AES key, and perform the encryption myself to verify this idea.
According to the documentation, this is the function definition of crypto::aes::cbc_encryptor.
pub fn cbc_encryptor<X: PaddingProcessor + Send + 'static>(
key_size: KeySize,
key: &[u8],
iv: &[u8],
padding: X
) -> Box<Encryptor + 'static>
As shown above, this function takes 4 arguments, but in the decompilation below, it shows the function called with 5 arguments.
crypto::aes::cbc_encryptor::h211c41356831deed(2,&key,0x20,&iv,0x10);
After taking some time being confused, I realized each argument that is an array takes up 2 arguments, 1 for the buffer and 1 for the array size. I suppose the padding argument is optional so it is not present here. Anyways, knowing this, I could now inspect the contents of the key. I know that the key is 32 bytes because that was the value passed as the 3rd argument.
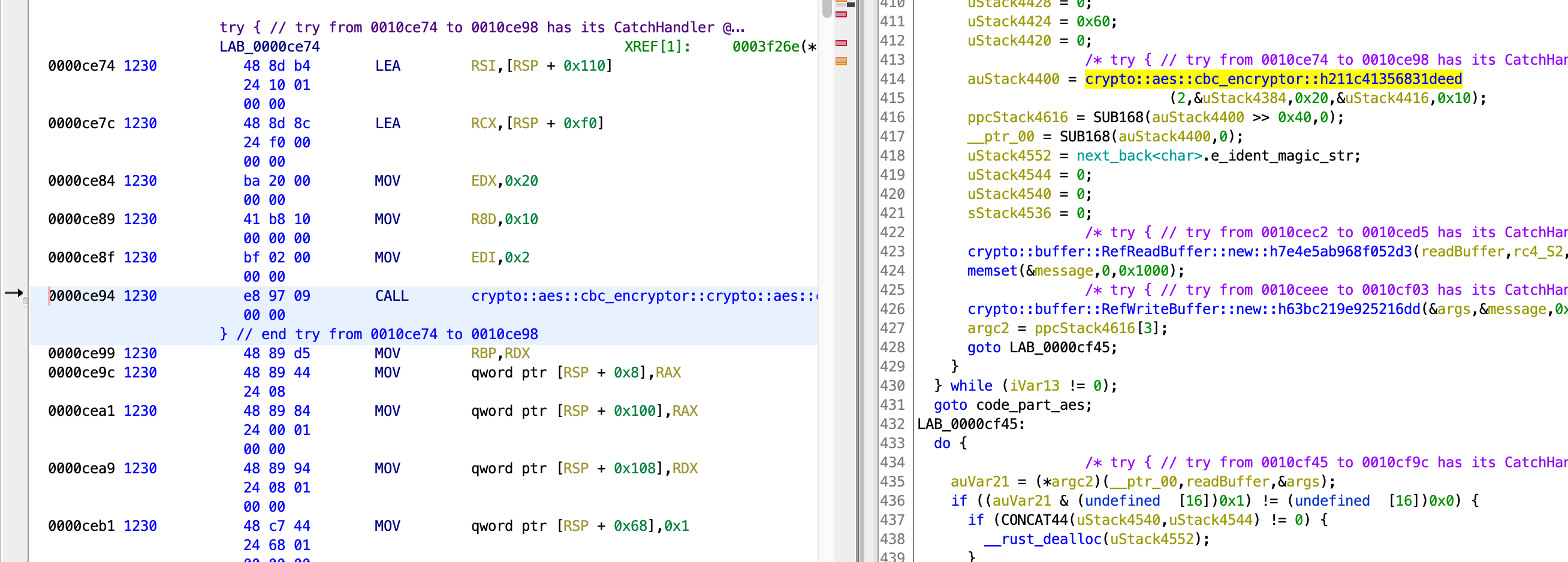
gef➤ pie break *0xce94
gef➤ pie run inctf{}
gef➤ x/32bx $rsi
0x7fffffffc830: 0xec 0xad 0xe9 0x18 0xdb 0xfa 0xbf 0x53
0x7fffffffc838: 0x03 0x4f 0x65 0x4b 0xef 0x52 0x32 0x92
0x7fffffffc840: 0xae 0xc1 0xc4 0xd0 0x13 0xdd 0x5d 0x28
0x7fffffffc848: 0x05 0xea 0x53 0x97 0x14 0xe0 0x6d 0xd1
Now things are slightly tricky. I want to know what is being encrypted to give the final output found earlier. Is it my original input, or is my input mutated in some way? I decided to check the arguments to crypto::buffer::RefReadBuffer::new. Once again the documentation says pretty much nothing about this class so I just had to try.
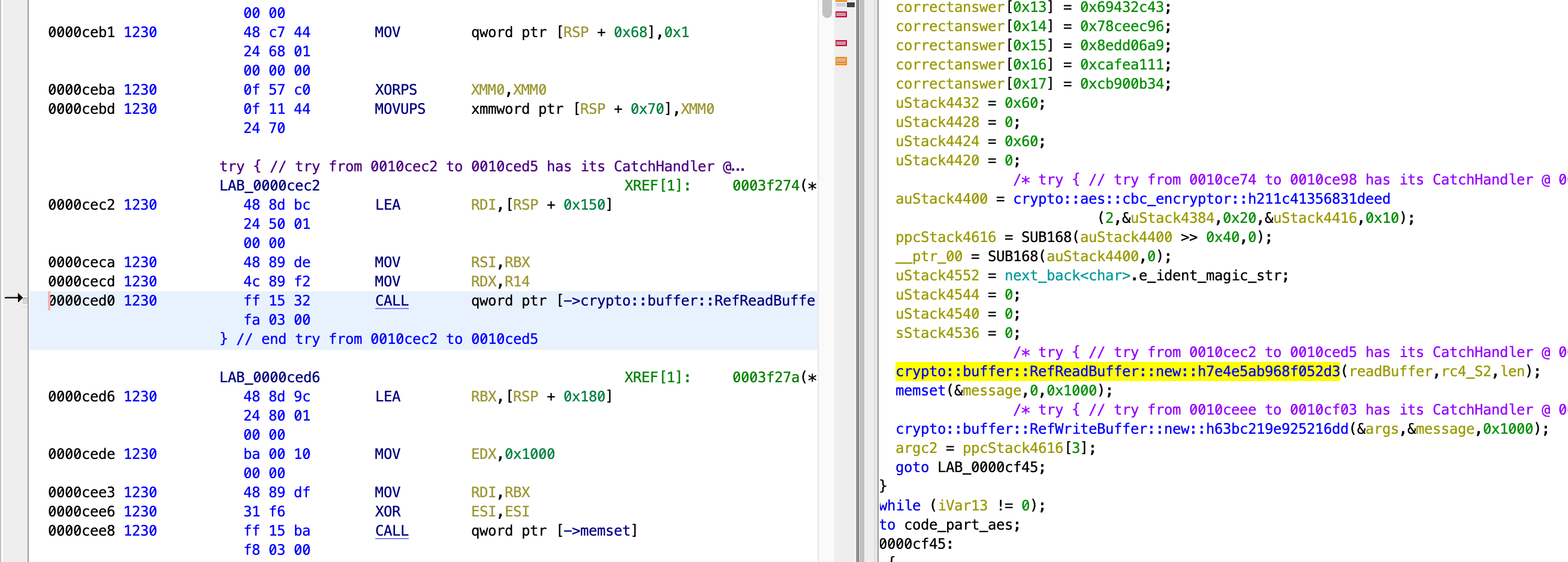
It didn’t take too long to realize that the contents of the 2nd argument changes according to my input, and has the same length as my input. Interestingly, the contents start the same for inputs that start the same, as we can see when the inputs are inctf{} and inctf{a}. However, this is not the case if they start differently, when the inputs are inctf{} and abcdefg.
gef➤ pie break *0xce94
gef➤ pie run inctf{}
gef➤ x/32bx $rsi
0x5555555a60e0: 0x2b 0xb5 0xa2 0xeb 0x68 0xeb 0x11 0x00
0x5555555a60e8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555a60f0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555a60f8: 0x21 0x00 0x00 0x00 0x00 0x00 0x00 0x00
gef➤ x/32bx $rsi
gef➤ pie run inctf{a}
0x5555555a60e0: 0x2b 0xb5 0xa2 0xeb 0x68 0xeb 0x5d 0x9d
0x5555555a60e8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555a60f0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555a60f8: 0x21 0x00 0x00 0x00 0x00 0x00 0x00 0x00
gef➤ pie run abcdefg
gef➤ x/32bx $rsi
0x5555555a60e0: 0xd7 0x31 0xa2 0xbf 0x82 0x16 0x1b 0x00
0x5555555a60e8: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555a60f0: 0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00
0x5555555a60f8: 0x21 0x00 0x00 0x00 0x00 0x00 0x00 0x00
This means each byte of the buffer has a direct correspondence to each byte in the input, but also depends on what happened to the bytes before it. This resembles the behaviour of RC4, although it most likely isn’t since the code doesn’t look like it.
To confirm that I got the correct key, I opened up cyberchef and passed in the key and iv used by the program, tried to encrypt the bytes gotten above, and observed that the encryption output obtained in cyberchef is indeed the same as the one in the program.
Time to find the flag
Now, I know that the program
- Takes my input
- ??? Does something to my input ???
- Encrypts it with AES CBC
- Compares it with another array
Step 2 above should be the part where things happened with the random number generator. I didn’t really plan on fully reversing that part, as I felt that it wasn’t really necessary to do this to get the flag. Instead, I can do some form of brute force searching to find the flag.
First, I decrypted the “correct array” using cyberchef, and got the following.
2b b5 a2 eb 68 eb c9 6e c7 31 98 ae 71 05 22 a4 d0 b0 06 7e 42 79 bc cc
e7 cd c1 92 7e a9 89 ee 2b f7 43 32 3f 09 b3 17 ee df 13 9f f8 ae 31 9f
ad e4 d3 c0 a4 e6 0c d8 7e 1e 09 2d fa 3a 68 f4 7e b6 67 44 a1 fe 24 7b
12 d4 dd 99 88 ee df 13 ac 1b 23 48 f5 9d d7 4f
Now, I just need to find the correct input that is transformed into the bytes above. You might notice that the bytes above start with 2b b5 a2 eb 68 which is the same when the input starts with inctf. This means that I am on the right track.
To get the flag, I can try inctf{a, inctf{b, inctf{c, and so on until the input is transformed into something that matches the bytes above. Just do this for every byte until I get the whole flag.
In the past, I liked writing GDB scripts to automate this brute-force process. I used to do this in the GDB scripting language, but always had to refer back to previous scripts because I can’t remember the correct syntax. This time, I decided to write my script in python and it felt way better.
import string
cs = string.ascii_letters + string.digits + "{}_!@"
d = "2bb5a2eb68ebc96ec73198ae710522a4d0b0067e4279bccce7cdc1927ea989ee2bf743323f09b317eedf139ff8ae319fade4d3c0a4e60cd87e1e092dfa3a68f47eb66744a1fe247b12d4dd9988eedf13ac1b2348f59dd74f"
flag = ""
gdb.execute("gef config context.enable 0")
for i in range(len(d)//2):
for c in cs:
gdb.execute("run {} > /dev/null".format(flag + c))
m = gdb.execute("x/bx $rsi+{}".format(i), to_string=True).strip().split(":\t0x")[1]
if m == d[i*2:i*2+2]:
flag += c
print(flag)
open("flag.txt", "w").write(flag)
break
Tricks to make GDB “quieter”
When running the script, GDB prints a message whenever I hit a breakpoint. This feels quite annoying since the script hits the same breakpoint hundreds of times. To suppress this output I used the following script to set the breakpoint.
break *0x555555554000+0xced0
commands
silent
end
Now to get the flag, I just ran the following (-batch suppresses some more output compared to -quiet which is commonly used)
gdb -batch ./jazz -ex "source silentscript" -ex "source solve.py"
After waiting for around 15 minutes (since I’m running this in a VM, and there are 88 characters in the flag), I got the flag.
inctf{fly_m3_70_7h3_m00n_l37_m3_pl4y_4m0n6_7h3_574r5_4nd_l37_m3_533_wh47_5pr1n6_15_l1k3}