Exploiting Out of Order Execution
The following are my notes for the talk Exploiting Out of Order Execution: Processor Side Channels to Enable Cross VM Code Execution by Sophia D’Antoine in REcon 2015.
The Cloud
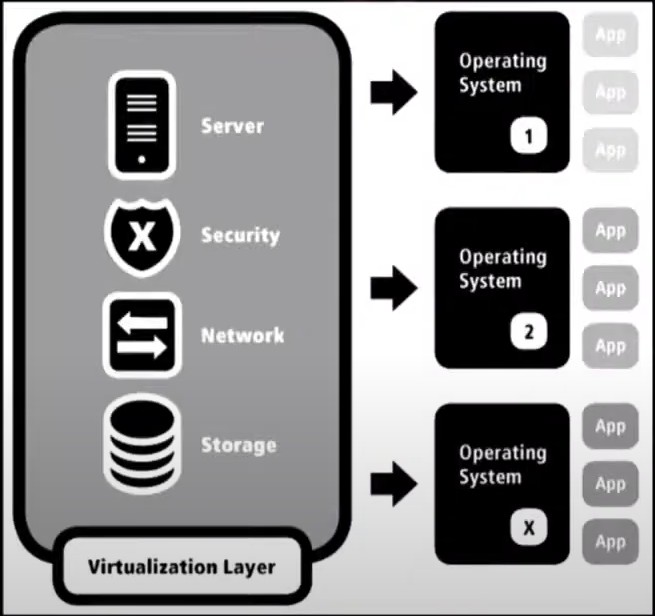
Bunch of virtual instances/virtual machines, all resting on shared hardware, allocated by the hypervisor. They are dynamically allocated.
Problems
Security issues
- Sensitive data stored remotely
- Vulnerable host
- Untrusted host
- Co-located with foreign VMs, sharing resources with instances we don’t know
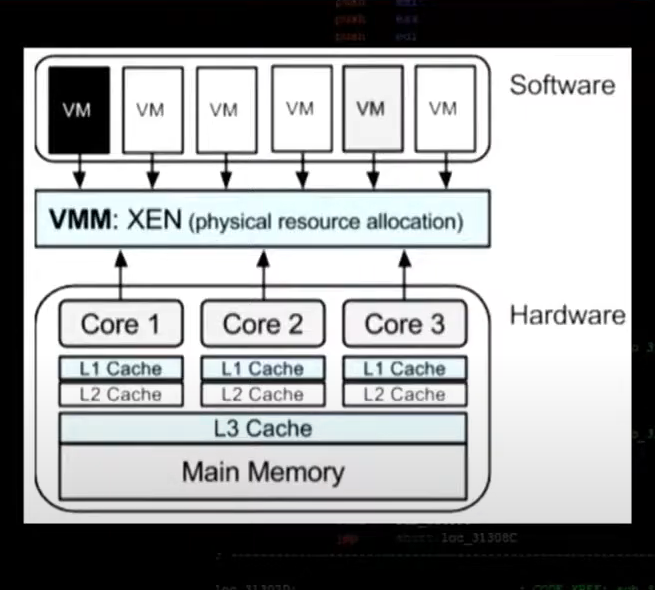
Physical co-location leads to side channel vulnerabilities.
Basic cloud hardware structure
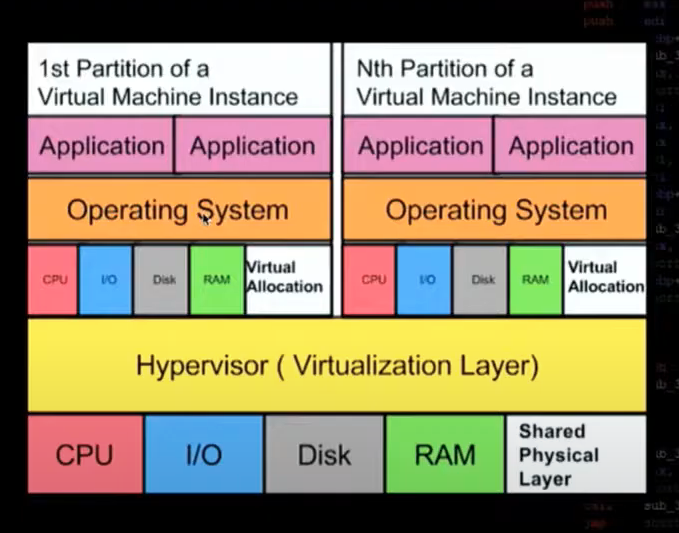
Universal Vulnerabilities
- Translation between physical and virtual hardware based on need.
- Allocation causes contention. One virtual machine can cause contention for another.
- Private VM activities are not opaque to other instances on the same hardware.
Can do side channel attack.
- Hardware side channel. The physical environment surrounding the VMs is what’s leaking information.
- Cross virtual machine. Each VM is like a blackbox to other VMs, but they can learn about the surrounding environment.
- Information is gained through recordable changes in the system.
- Information must be both recordable and repeatedly recordable.
- Must be able to map information to running processes with certain degree of certainty.
Classification Send/Receive Model
Can implement a send/receive model.

Possible exploits
Receive (exfiltrate)
- Crypto key theft
- Process monitoring
- Environment keying. Create a unique signature from the environment, and use it to identify the server
- Broadcast signal
Transmit (infiltrate)
- DoS (clog up pipeline/cache so that other VMs cannot access resources)
- Co-residency
Transmit & Receive (network)
- Communication (C&C)
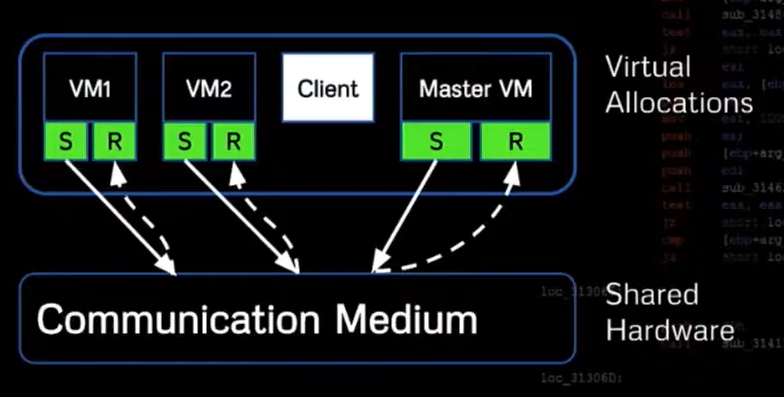
VM1 and VM2 are sending artifacts, Master VM is reading the results, creating meaning from them.
Cache Side Channel Example
Flush+Reload targets the L3 Cache Tier.
Receiver (adversary) flushes & queries L3 line. Transmitter (Victim) access same L3 line. GnuPG private key leaked.
More info at sophie.re/cache.pdf
Pipeline side channel
Benefits of using pipeline vs cache
- Quiet, covert channel. Easier to detect if someone is interacting with the cache, because it is easier to query.
- Not affected by cache misses.
- Amplified in a noisy environment (esp. in the cloud because a lot of instances are interacting with the same hardware)
Attack Vector
Create a side channel to exploit inherent properties of the hardware medium.
Requirements:
- Shared hardware
- Dynamically allocated hardware resources
- Co-location with adversarial VMs or infected VMs
Target the processor as the hardware medium
- CPU’s pipeline
- Difficulty: Query the system artifcats dynamically. No easy way to query the pipeline at a specific state, because will interfere with the pipeline.
Extract information
- Instruction set
- Result from instruction sets
Can use out-of-order-execution. This is the artifact that we are forcing to the pipeline, to learn about the state of the pipeline, and about other processes sharing the pipeline.
Processor Pipeline Contention
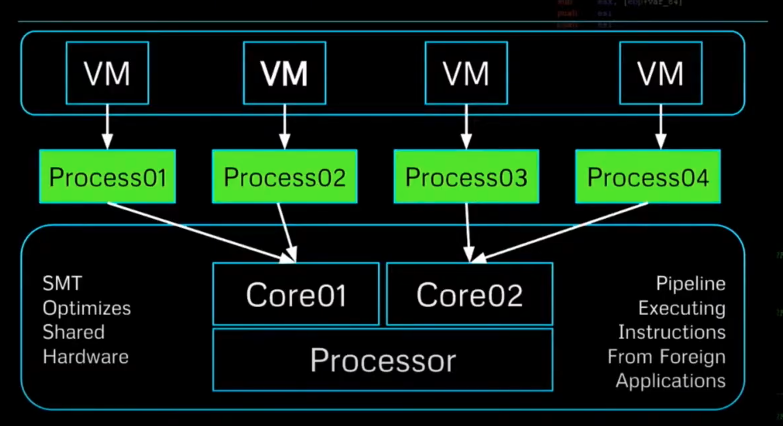
VM processes sharing hardware. Our instructions in the cloud are executed with instructions from other foreign VMs we know nothing about.
Receiver (Record Out of Order Execution)
Can get a case of out-of-order execution with the following behaviour. And this is something that can be recorded.

An example:
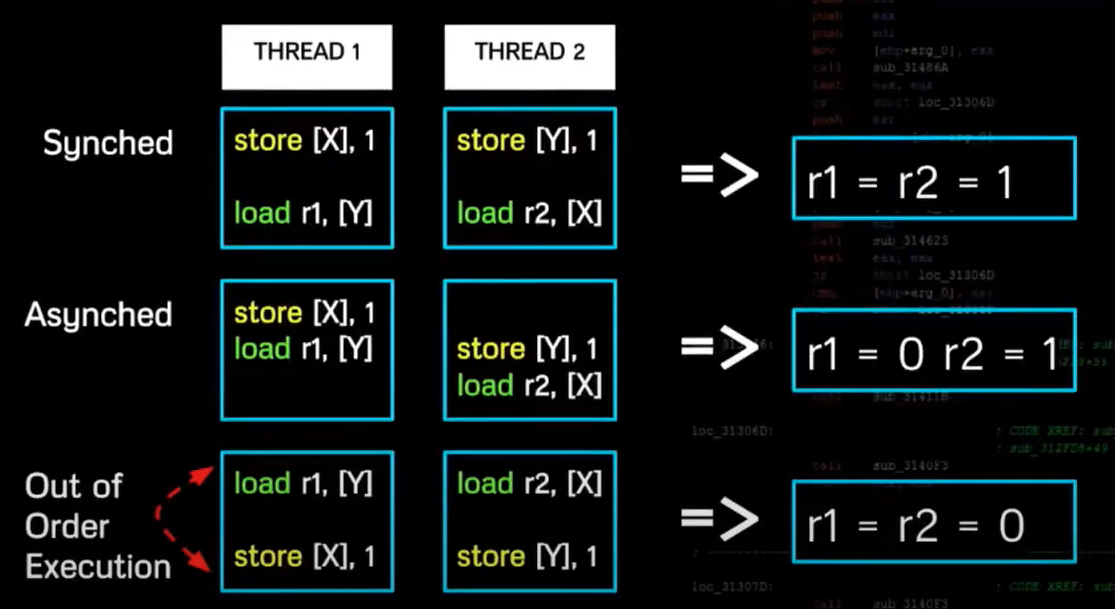
First 2 cases are ok, there is no reordering. But for the final case, there is out of order execution.
Pseudo-code of receiver checking for the out of order scenario:
int X, Y, count_OoOE;
// ... initialize semaphores Sema1 & Sema2 ...
// thread1 and thread2 are as the example above
pthread_t thread1, thread2;
pthread_create(&threadN, NULL, threadNFunc, NULL);
for (int iterations = 1; ; iterations++)
{
X,Y = 0;
sem_post(beginSema1 & beginSema2);
sem_wait(endSema1 & endSema2);
if (r1 == 0 && r2 == 0)
count_OoOE++;
}
We can use this to get a count of the average out-of-order executions received in a specific time frame, and use this to learn what an expected average should be, analogous vs anomalous.
Transmitter (Force Out of Order Execution to change)
Can decrease the amount of out of order execution using mfence.
mfence:
- x86 instruction full memory barrier prevents memory reordering of any kind
- order of 100 cycles per operation
- use #StoreLoad barrier to prevent r1=r2=0 case
The pipeline is like this:
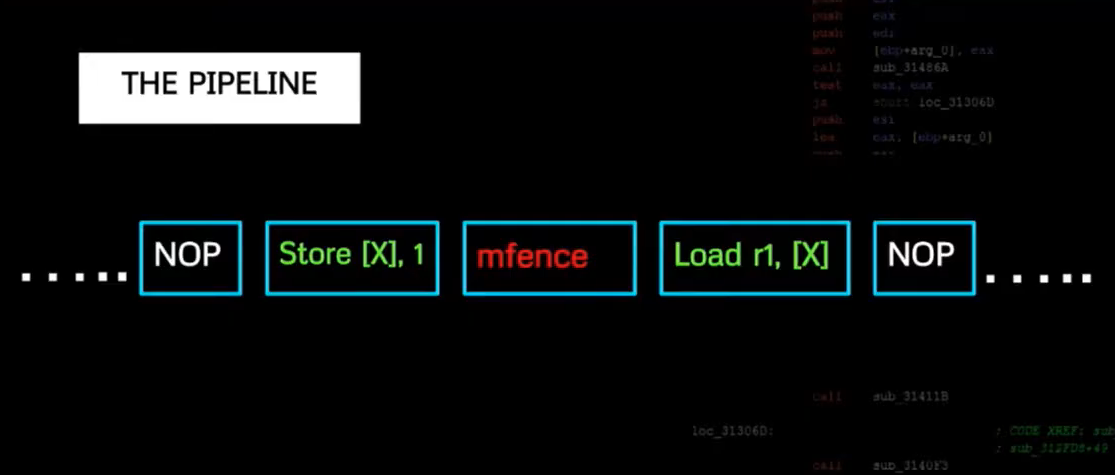
The transmitter is forcing the memory fences in the same pipeline and the same time frame as the receiver is recording.
Transmitter (victim):
- Force Out-of-Order execution patterns
- Affect the order of stores and loads
- Time frame dependant
- Using mfence
Design a channel
Used Xen hypervisor, Xeon processors, shared multi-core/multi-processor hardware
- 8 logical CPUs/4 cores
- 6 Windows 7 VMs
- (Simultaneous multi-threading) SMT is turned on
Virtual Machine S/R Model:
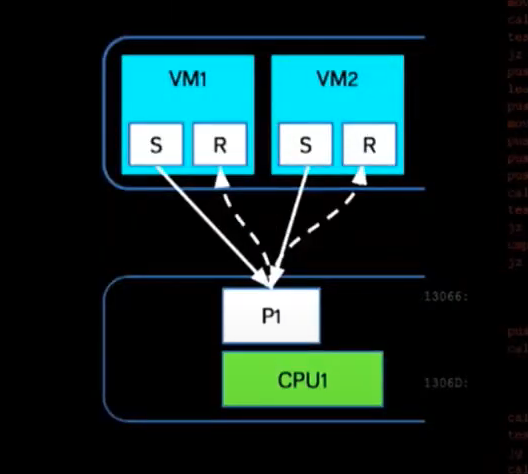
Because the side-channel is over the pipeline, the send & receive both have to be on the same pipeline.
Potential Channel Mitigation
- Isolate VMs in different hardware
- Turn off hyperthreading/SMT
- Blacklist resources for concurrent threads
But will lose out on the benefits of sharing resources.
My thoughts
I don’t really know what is the impact of this side channel. I shall find out more in her thesis paper.