T19 Challenge - Part 3
This is the third part of the writeup for the T19 Challenge, and here is part 1 and part 2.
Previously, we managed to gain shell access to the server as the user rubyist, by being able to execute arbitrary commands through the web application. After that, we exploited a buffer overflow in the dbclient binary to escalate privileges as user ben. In this part, we will exploit a buffer overflow in the virus database service.
Reverse Engineering
Downloading the binary
Earlier, it was said that they heard ben was working on the running server, which would be srv_copy found in ben’s home directory.
rubyist@t19-deployment-7b944c57cb-h5vjr:~$ ls -al /home/ben
total 60
drwxr-xr-x 1 ben ben 4096 Jan 15 16:19 .
drwxr-xr-x 1 root root 4096 Dec 26 15:26 ..
-rw-r--r-- 1 ben ben 220 May 15 2017 .bash_logout
-rw-r--r-- 1 ben ben 3526 May 15 2017 .bashrc
-r----S--- 1 ben ben 24 Nov 29 15:00 .flag.advanced
-rw-r--r-- 1 ben ben 675 May 15 2017 .profile
-rws---r-x 1 ben ben 14872 Dec 17 18:01 dbclient
-r-------- 1 ben ben 14552 Jan 15 16:19 srv_copy
We can download the binary using the method describe in part 2.
Analysing the binary
Here is the pseudocode for srv_copy.
int main(int argc, char** argv)
{
char message[269];
while ( 1 )
{
fd = start_server("secretSock");
if ( !fd )
break;
if ( fd > 0 )
{
while (read_message(fd, message))
{
switch(message.code)
{
case 1:
respond_client(fd, 1, 0);
break;
case 2:
char check_hash_result = check_hash(&message.data, &buf); // buf is in the .bss section
respond_client(fd, check_hash_result, 0LL);
break;
case 3:
char* hash_ptr = get_hash((long long) message.data);
respond_client(fd, 1, hash_ptr);
break;
case 4:
char read_result = read_secret();
respond_client(fd, read_result, &secret);
break;
}
}
puts("server done with client.");
close_fd(fd);
}
else
{
fwrite("server can't start\n", 1uLL, 0x13uLL, stderr);
}
}
cleanup();
puts("server quit.");
return 0LL;
}
In the previous part the implementation details of the client-server communication was omitted. For this part we need to reverse engineer it so that we can write our own custom client to attack the server.
Running dbclient with strace, the socket api function calls can be easily identified. The program creates a UNIX domain socket, and we can easily replicate it.
const char* socketname = "secretSock";
int fd = socket(1, 1, 0);
struct sockaddr_un addr;
memset(&addr, 0, sizeof(addr));
addr.sun_family = AF_UNIX;
strncpy(addr.sun_path + 1, socketname, strlen(socketname));
if (connect(fd, (struct sockaddr *) &addr, sizeof(sa_family_t) + strlen("secretSock") + 1) == -1) {
puts("failed connect");
return -1;
}
// http://man7.org/tlpi/code/online/dist/sockets/us_abstract_bind.c.html
During the challenge, I just used 13 which was the value I got from strace, instead of sizeof(sa_family_t) + strlen("secretSock") + 1. Only after the CTF I decided to document the proper usage here.
UNIX domain sockets
Unlike TCP sockets that allow communicating with other devices over the internet, which we are more familiar with, UNIX domain sockets allow for communication between processes on the same machine.
http://man7.org/linux/man-pages/man7/unix.7.html
The AF_UNIX (also known as AF_LOCAL) socket family is used to communicate between processes on the same machine efficiently. Traditionally, UNIX domain sockets can be either unnamed, or bound to a filesystem pathname (marked as being of type socket). Linux also supports an abstract namespace which is independent of the filesystem.
You may have noticed that one byte was skipped in strncpy(addr.sun_path + 1, ...). This is to indicate the usage of an abstract namespace. Otherwise, a typical UNIX domain socket would create a file that actually appears in the filesystem, which would be troublesome to connect considering it is bound to a filesystem pathname.
More information could be found here.
Message format
Client
The server receives a 269-byte buffer from the client, which can be represented by the following struct.
struct ClientMessage
{
long long checksum; // an adler32 checksum is computed and stored here
char dummy[5]; // this is the same throughout all requests and is not processed by the server
char code; // request code
char[255] data; // could be a string or an integer
}
void request_server(int fd, char code, char *data)
{
struct ClientMessage s;
memset(&s, 0, 269);
memcpy(&s.dummy, "DA777", 5);
s.code = code;
if (data)
{
memcpy(&s.data, data, 255);
}
long long checksum_init = adler32(0, 0, 0);
s.checksum = adler32(checksum_init, &s, 269);
write(fd, s, 269);
}
Each ClientMessage contains a request code to indicate the operation performed by the server, followed by a generous 255-byte buffer of data. Just before the client sends the message, it will compute a checksum and store it in the message itself.
When the server receives the message, it first computes a checksum of the message and compare it with the sent checksum. This is to verify that the message is sent from dbclient itself.
Server
The server responds the client with a 255-byte buffer.
struct ServerResponse
{
char result; // 0 or 1
char[255] data;
}
void respond_client(int fd, char result, char *data)
{
struct ServerResponse s;
memset(&s, 0, 256);
s.result = result;
if (data)
{
memcpy(&s.data, data, 255);
}
write(fd, s, 256);
}
The response by the server is slightly simpler, with just 1 byte indicating the result and 255 bytes of data following it.
Troublesome read and write
Request codes 2 and 3 contain vulnerabities that could be used to perform a write and read, respectively.
case 2:
char check_hash_result = check_hash(&message.data, &buf); // buf is in the .bss section
respond_client(fd, check_hash_result, 0LL);
break;
case 3:
char* hash_ptr = get_hash((long long) message.data);
respond_client(fd, 1, hash_ptr);
break;
Write
Let’s look at the write vulnerability in check_hash first.
void init_db()
{
if (db)
return 1;
fd = open("/opt/db/base", 0);
fstat(1, fd, &stat_buf);
len = stat_buf.st_size;
db = mmap(0LL, stat_buf.st_size, PROT_READ|PROT_WRITE, MAP_PRIVATE, fd, 0);
close(fd);
}
int check_hash(char* input, char* buf)
{
char dest[32];
int index;
char* copy_buf;
init_db();
index = 0;
copy_buf = buf;
strcpy(&dest, input);
do
{
strcpy(copy_buf & 0xFFFFFFFFFFFFFFF0, &db[index]);
if (!memcmp(&dest, copy_buf, 0x20))
return 1;
index += 0x21;
}
while (db[index]);
return 0;
}
With message.code set to 2, the program first calls init_db() to map the contents of opt/db/base into memory, and saves the address into the global variable db. A check is made to ensure this is only ran once.
Our sent message.data is copied into a variable on the stack, dest. After that, 20 bytes will be copied from db into copy_buf, which is then compared with the contents in dest. The index is incremented by 0x21 (includes the null byte), and the process above is repeated until we get a match, or there is nothing left in db.
The line that catches my attention is strcpy(&dest, input). By overflowing the buffer in dest, we can overwrite the variables index (where to copy from), and copy_buf (where to write to). The only constraint here is there cannot be null bytes present in the new index, or strcpy wouldn’t overwrite the contents of copy_buf.
Read
Moving on, let’s look at the read vulnerability in get_hash.
char *get_hash(unsigned long long index)
{
return &db[0x21 * index];
}
With message.code set to 3, we can send an integer in message.data to specify the index of the db to read from. Except that there is no boundary checking made.
Simple enough, we can provide a large index to read other unintended parts of memory. One problem here is the 0x21 multiplier being applied, which is kind of limiting.
I overcame this by finding the modular multiplicative inverse of 0x21 under modulo 2**64, i.e. finding a value x such that (x * 0x21) % (2 ** 64) == 1, so that I can specify the exact offset to read from (since everything above 8 bytes is truncated during multiplication).
// since 1117984489315730401 * 0x21 = 1
// 0x21 * 1117984489315730401 * offset = offset
index = 1117984489315730401 * offset;
// db[0x21 * index] = db[offset]
Alternatively, as the server copies all 255 bytes from the pointer returned by get_hash into the response, instead of using strcpy which stops once reaching a null byte, one can also just extract from the desired offset after reading from the server. (I believe so, but may be wrong as I didn’t check.)
Secret
void read_secret()
{
init_db();
if (*db)
{
fd = open("/opt/db/.flag.pwn", 0);
read(fd, &secret, 0xFF);
close(fd);
}
else
{
memset(&secret, 0, 0xFF);
}
}
With message.code set to 4, the server checks if db is empty. If so, it reads the flag into a global variable secret, which will then be sent to the client as response.
Seeing this and the challenge description to empty their database, it is clear that our task is to overwrite the first byte in db to a null byte, so that effectively the database is “emptied”.
Exploit
Now the attack plan is straightforward. Find out where is db, then overwrite it with a null byte.
Finding db
This part took me a few hours, as I went down the completely wrong path of trying to locate the address of the ld section by scanning the stack for specific bytes, then subtracting with supposed offsets, as the ld section is “close” to db when inspecting with gdb. This was really unproductive as the challenge server probably had mapped them differently from my local machine, making it hard to effectively predict how “far” they are apart.
Only after a while I decided to look at the memory page directly below db, and immediately found treasure.
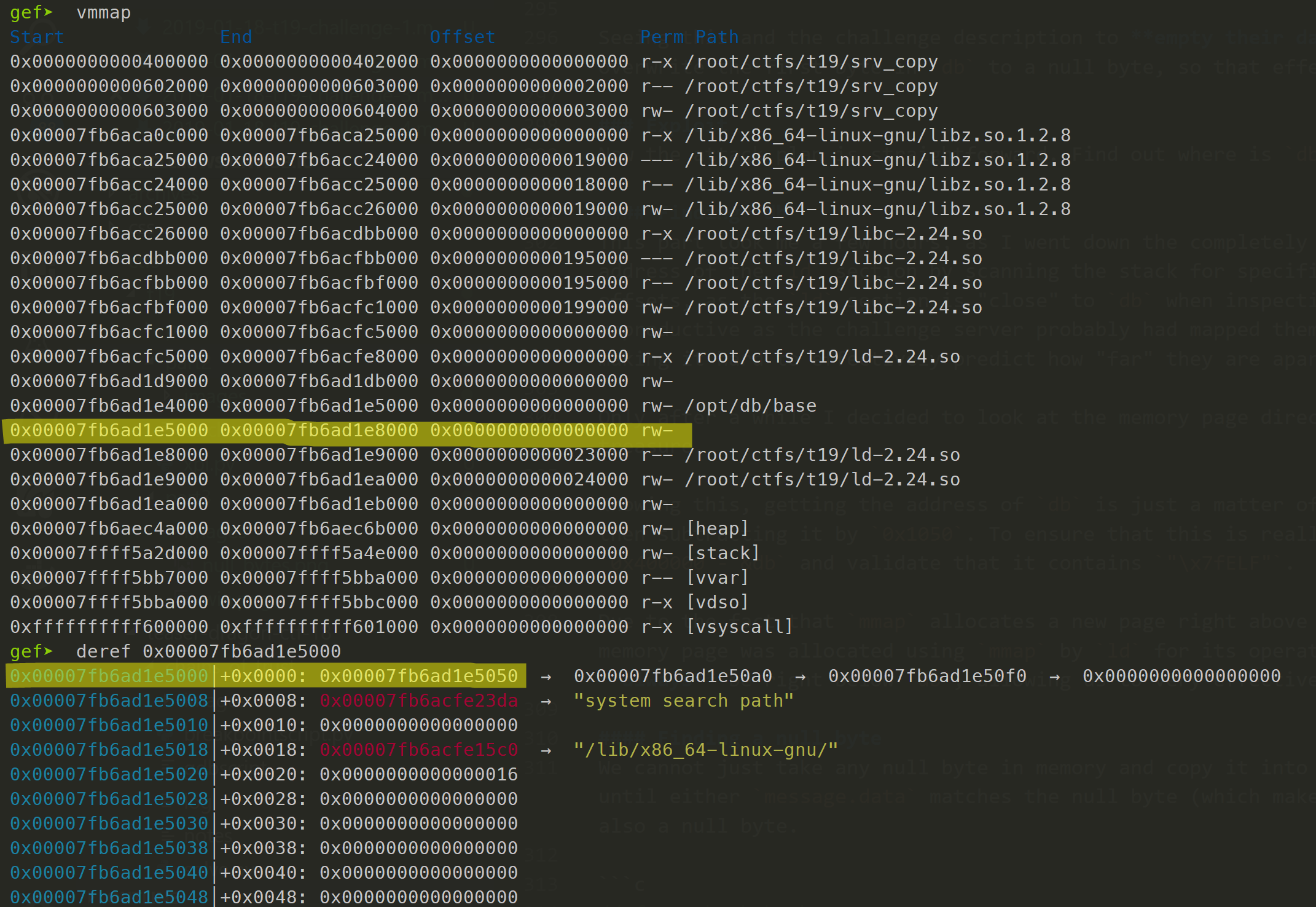
Knowing this, getting the address of db is just a matter of reading the address at offset 0x1000, then subtracting it by 0x1050. To ensure that this is really correct, we can read from offset 0x400000 - &db and validate that it contains "\x7fELF".
Due to the fact that mmap allocates a new page right above the previously allocated one, and this memory page was allocated using mmap by ld for its operations, I am quite certain that it will always be right below db, allowing us to very effectively determine the exact address of db.
Checking this a couple of times locally and on the challenge server proved my point.
Finding a null byte
We cannot just take any null byte in memory and copy it into db, since the program will keep copying until either dest matches the null byte (which makes no sense), or the next entry is also a null byte.
// from check_hash
do
{
strcpy(copy_buf & 0xFFFFFFFFFFFFFFF0, &db[index]);
if (!memcmp(&dest, copy_buf, 0x20))
return 1;
index += 0x21;
}
while (db[index]);
In other words, we need to find an address that contains a null byte, then address + 0x21 must also contain a null byte. Unfortunately, we cannot use the memory page mentioned earlier, despite it having an abundance of null bytes, because its offset from db is in the range of 0x1000 to 0x2000, which is less than 8 bytes long, meaning that there will be null bytes when overwriting index in check_hash.
However, there are references to strings in the ld section in this page, which we can use to determine the address of ld, which has a negative offset relative to db. Using any address in this section would be fine, since a negative value would fill up 8 bytes in memory.
To make sure that I am looking at the same thing the server is using, I downloaded /lib/x86_64-linux-gnu/ld-2.24.so from the challenge server, and started to look for the null bytes in gdb.
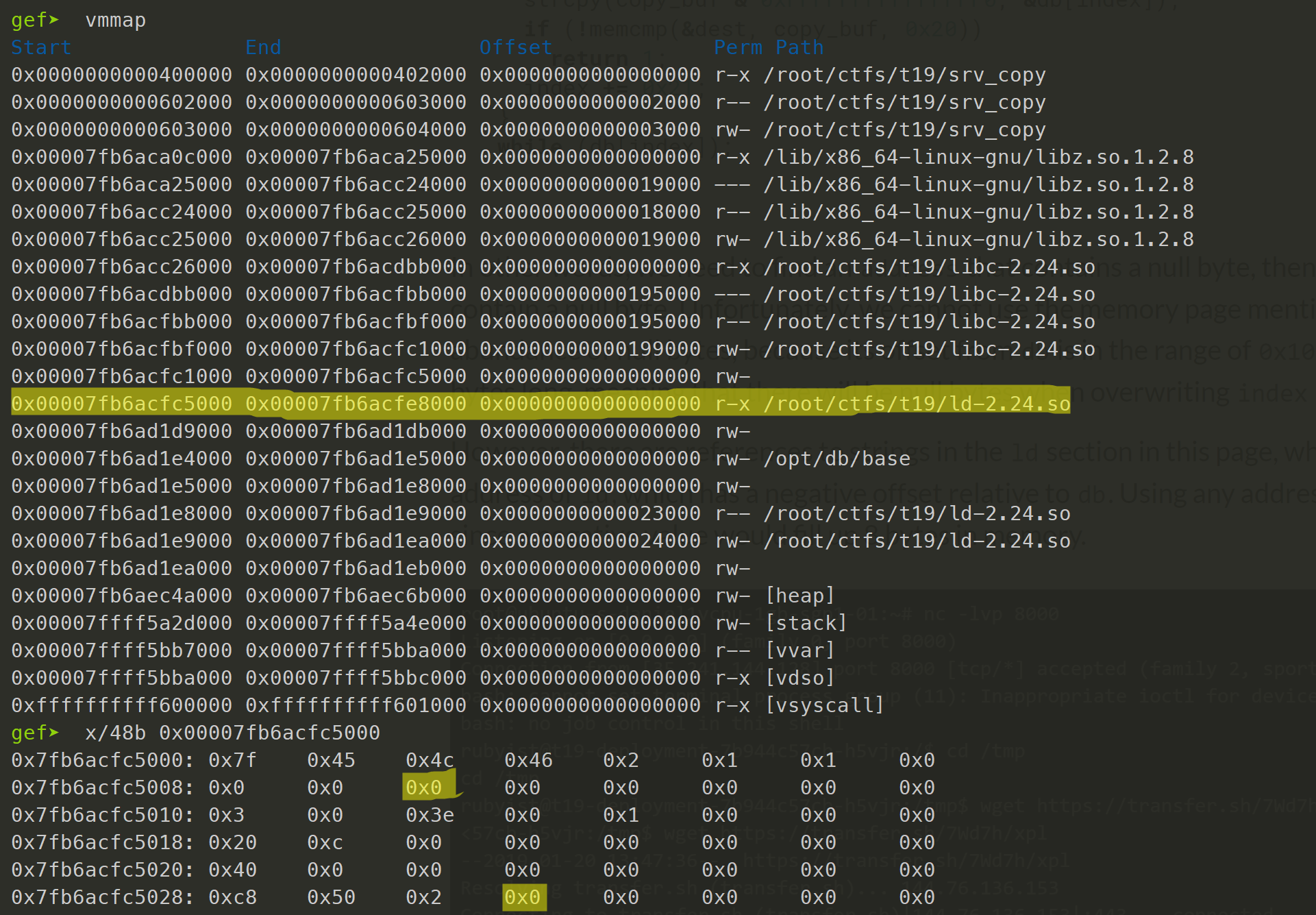
A working address can be found at ld + 0xa.
Wrapping things up
Now our exploit can be summarized in the following steps:
- Find address of
dbusing the memory page directly below it. - Find address of
ldusing addresses in that memory page. - Overflow
destto overwriteindexwith&db - (&ld + 0xa), andcopy_bufwithdb.

The exploit code is quite long and messy, so I didn’t include them here, but you can find the relevant files here.
In the next part, we take one step further and exploit the server to get a root shell.
If there is anything unclear, feel free to leave a comment below.